| 体験セミナーの流れ
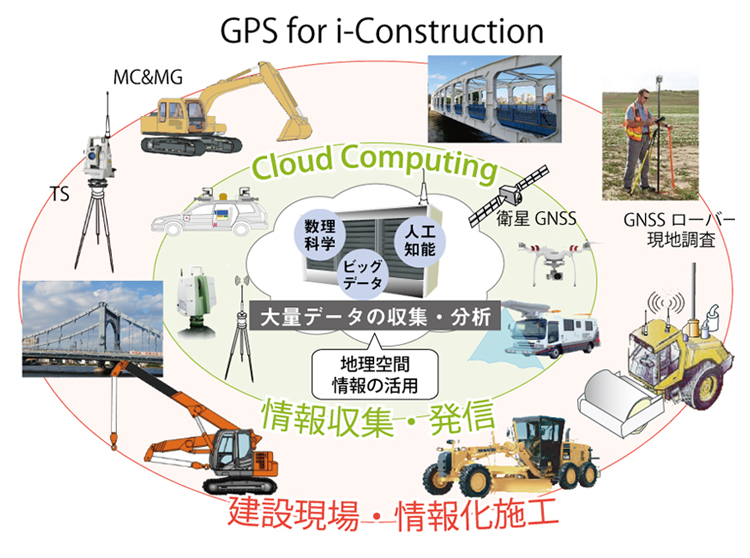
昨年の10月20日の午後1時半から4時半まで、Zoomによるオンラインセミナー「ビッグデータ解析体験セミナー」が開催されました。講師を務めたのは、フォーラムエイト UC-1開発第1Group長の中村淳さんと、システム開発Groupマネージャーの岡木勇さんです。
|
|
当日のスケジュールは、冒頭に中村さんがBIM/CIMの基礎知識や建設業のDXとの関係を解説した後、岡木さんにバトンタッチし、ビッグデータ解析の概要や事例を約30分解説しました。
その後、休憩をはさんで1時間20分ほど、「UC-win/Road」の運転ログデータや交通流シミュレーションデータをビッグデータとみなして分析体験を行いました。
そして最後にビッグデータの解析事例として、簡単なデータの可視化やUC-win/Roadとビッグデータの関係、道化整備効果の算出事例を紹介し、質疑応答で締めくくりました。
|
 |
| ▲10月20日にオンラインで開催された「ビッグデータ解析体験セミナー」の様子 |
|
| 体験内容
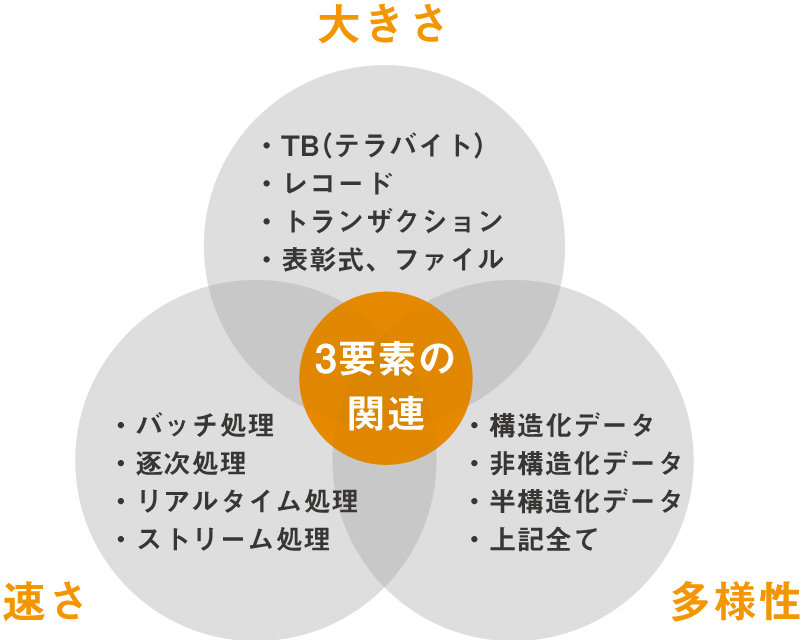
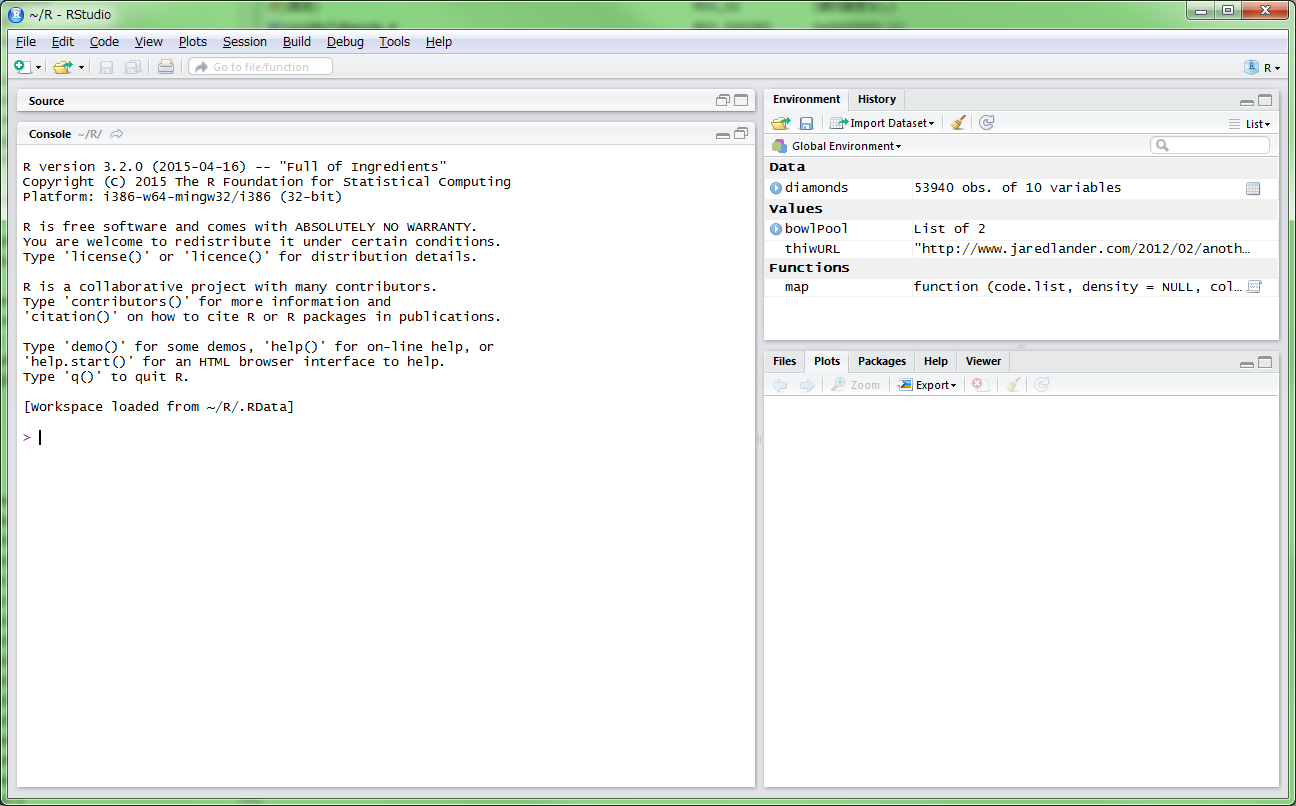
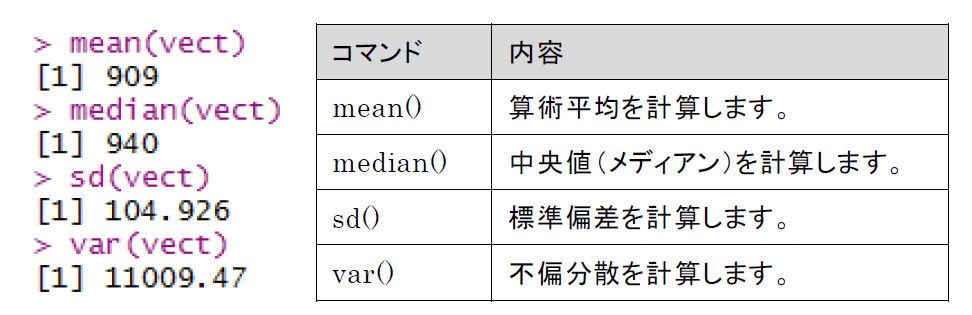
様々な様式からなる大量のデータから、特徴や傾向などをつかみ取るために、今回のセミナーでは「R言語」という聞き慣れないツールを使いました。R言語はコマンドラインで様々なデータ処理を行うもので、「R Studio」というソフトを立ち上げて操作しました。
|
 |
|
 |
| ▲「R Studio」の画面 |
|
▲R言語のコマンド例 |
|
|
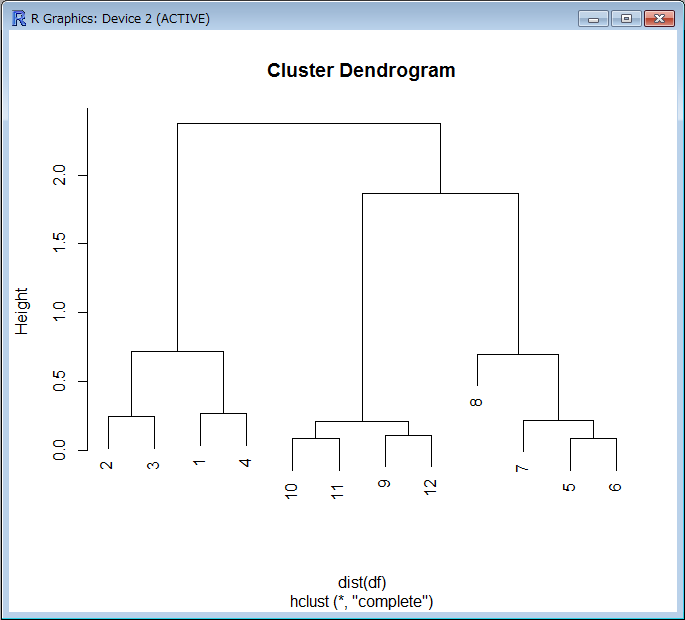
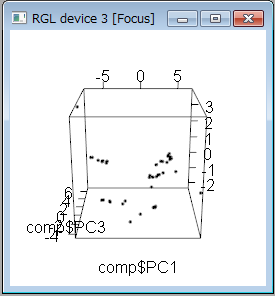
まずはビッグデータの傾向を可視化するための実習から始まりました。「pl ot 関数」による簡単なXY軸の2次元グラフの作成や、「hclust関数」などで似ているデータを分類する「階層的クラスター分析」、さらに“rgl
”ライブラリによる3次元でのデータ可視化を行いました。
|
 |
|
 |
| ▲似ているデータを分類する「階層的クラスター分析」の結果 |
|
▲“rgl”ライブラリによる3D表示の例 |
|
|
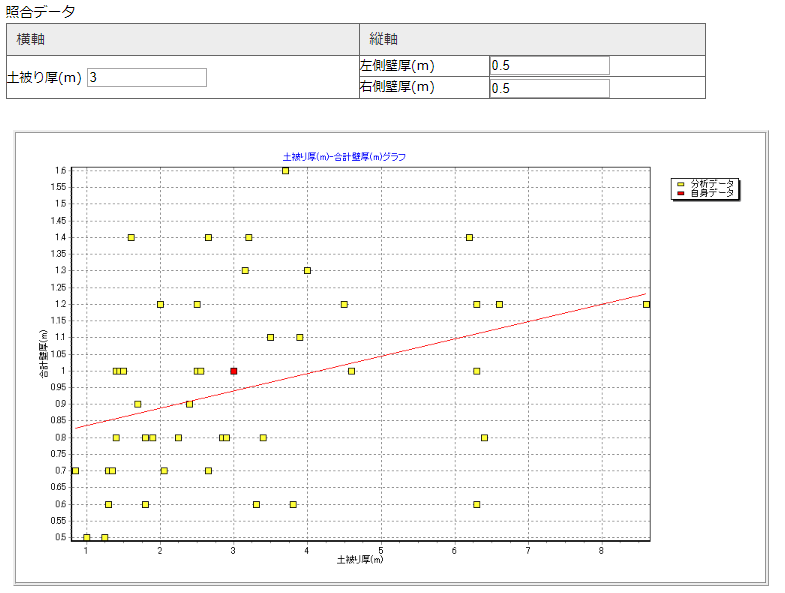
続いて、実際の土木構造物のデータを使って、ボックスカルバートの土被り厚と壁厚の関係をビッグデータ解析しました。フォーラムエイトの設計成果チェック支援システム「SystemA」からデータを読み込み、ボックスカルバートのデータを抽出します。
すると土被り厚と左右の合計壁厚のデータが2次元グラフとして表示されました。さらにR言語でデータを処理することにより、土被り厚や合計壁厚のほか、平均内空幅や内空高、内空幅高比をそれぞれ横軸、縦軸にとったグラフを一気に表示させました。多くのグラフを見ることで、データ間に相関関係がありそうかどうかを、視覚的に調べることができます。
|
 |
|
 |
| ▲横軸に土被り厚、縦軸にボックスカルバートの左右壁の合計厚をプロットしたデータ |
|
▲さらにデータの種類を増やして、X軸、Y軸を入れ替えて多数のグラフを表示させたところ |
|
|
さらに、これらのデータを「K平均法」という手法でクラスターに分類しました。これによって、ボックスカルバートの条件によって設計傾向に違いがあることが見えてきます。
|
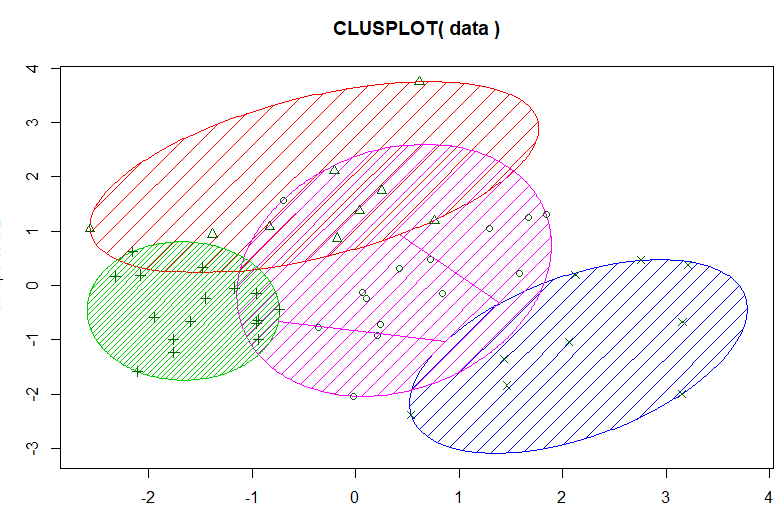 |
| ▲「K平均法」によるボックスカルバートのクラスター分類結果 |
|
|
続いて、天気のビッグデータ解析です。気象庁のウェブサーバーにアクセスして、天気データをダウンロードし、分析するものです。Excelなどの表計算ソフトでも行えますが、月ごとのデータをダウンロードしてコピー・アンド・ペーストし、分析するのは手間がかかります。
ここでは、汎用プログラミング言語の「Python」を使って、「ウェブスクレイピング」という手法によって必要なデータをサーバーから抜き出し、1年間の平均気温をグラフ化しました。ビッグデータ用のツールを使うことで、こうしたグラフをさっと作りながら傾向をつかむことができます。
|
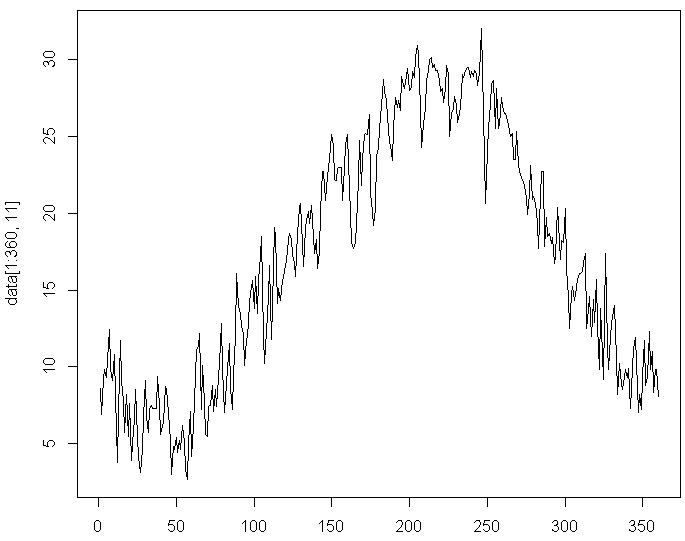 |
| ▲プログラミング言語「Python」を使って作成した1年間の平均気温グラフ |
|
|
操作研修はいよいよ交通流解析に移りました。「UC-win/Road」の走行データを使って、「急ブレーキ」についての調査を行いました。急ブレーキは接触事故の原因になるだけでなく、タイヤの消耗や燃費などに悪影響を与えます。ここではビッグデータから急ブレーキの原因が道路形状によるものなのか、他の自動車によるものなのかを検証しました。
運転ログのデータは、CSV形式のテキストデータになっており、1つのデータには時刻や各方向への速度や加速度、車体の傾き角、車線との距離など約60項目のデータが記録されています。ここから1台のクルマの情報を、ID番号を手がかりに抽出し、走行状態を追跡してみました。
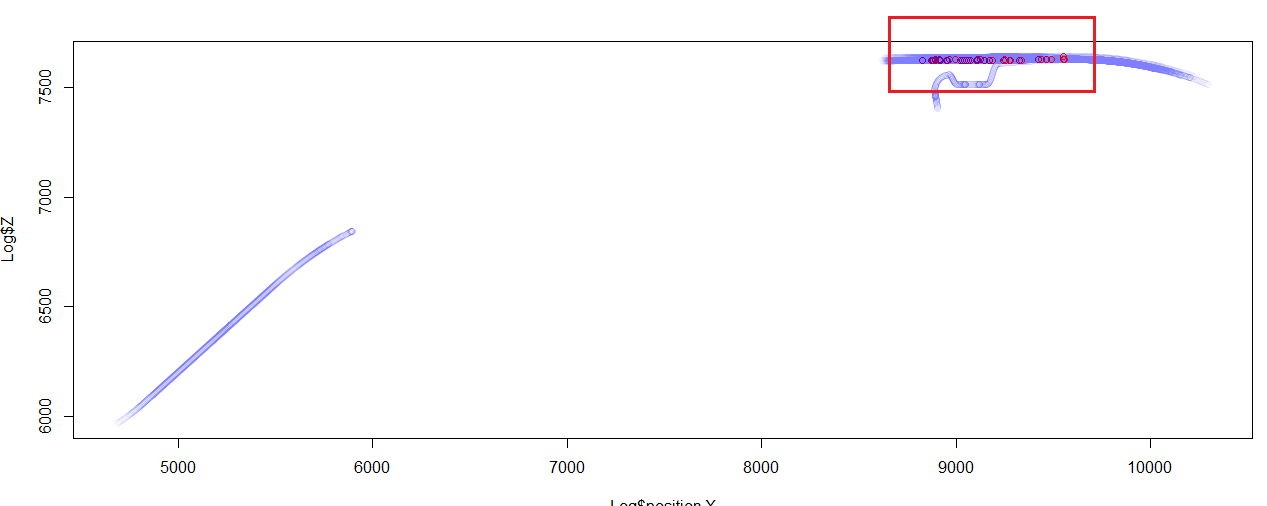
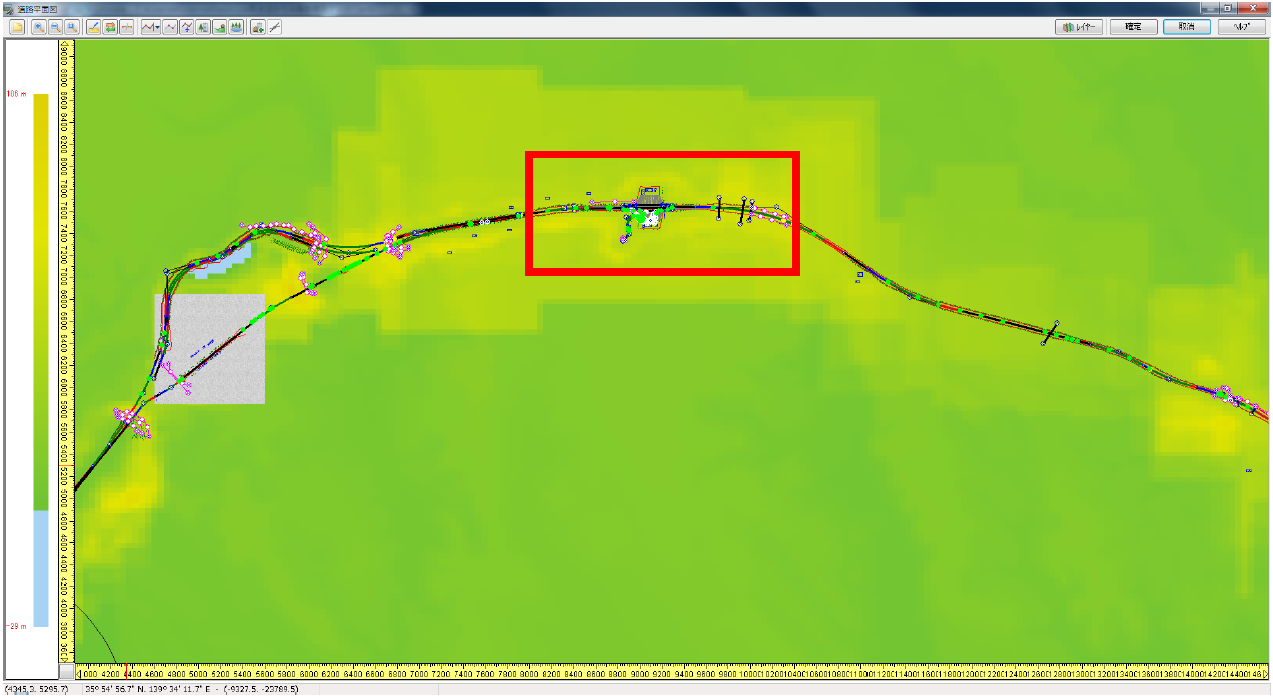
今度は全車両を対象に急ブレーキをかけたデータを抜き出してみました。0.4G以上の加速度が発生したときに「急ブレーキ」とみなしました。急ブレーキが多い場所をUC-win/Roadのモデル上に表示すると、パーキングエリアの横の道路であることがわかりました。
|
 |
|
 |
| ▲赤枠内が0.4G以上の急ブレーキ発生が多い場所 |
|
▲UC-win/Roadのモデル上で急ブレーキ発生多発地点を見ると、パーキングエリアの横の道路であることが判明した |
|
|
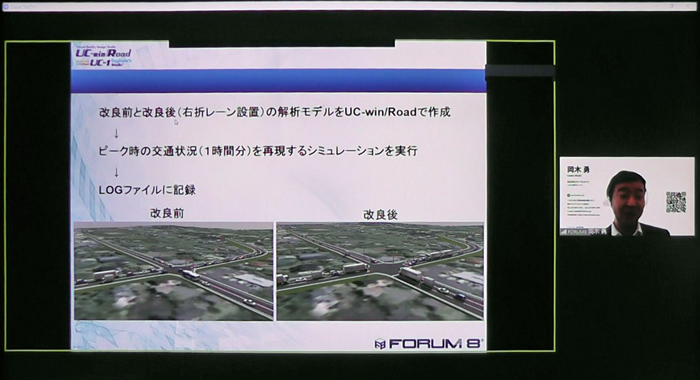
実習の最後には、ビッグデータを使った道路整備効果の算出を講師がデモンストレーションしました。ある交差点に右折レーンを設置した場合、交通流がどれだけ改善されるのかを評価しようというものです。
交通シミュレーションだけでも、その交差点の渋滞長がどれだけ減少するのかといったことはわかりますが、ビッグデータ解析を使うことで、周辺を走行するクルマ全体の通過時間の減少や、渋滞の減少によるコスト改善の効果を定量的に評価することができます。
|
 |
|
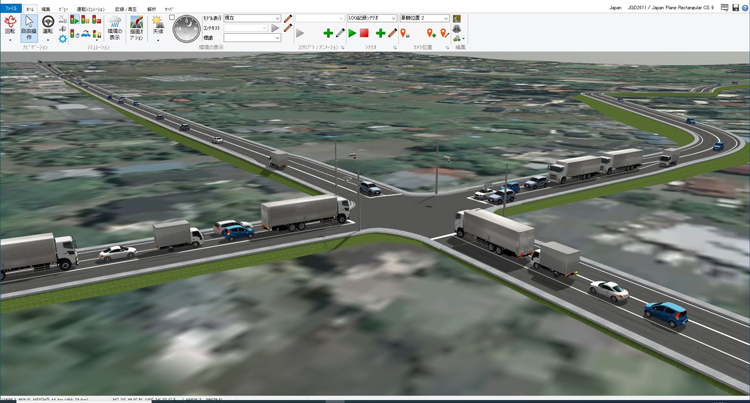 |
| ▲交差点に右折レーンを設ける前(左)と後(右)の交通流シミュレーション結果もビッグデータとして様々な投資効果の解析に使える |
|
|
右折車線の設置前と設置後の交通流シミュレーション結果の分析には、Pythonで書かれたプログラムで1時間かかります。その結果は、とても興味深いものでした。右折車線を設けた結果、全ての車種で平均速度が向上したほか、1日当たりの走行費用も明らかに減ることがわかったのです。
|
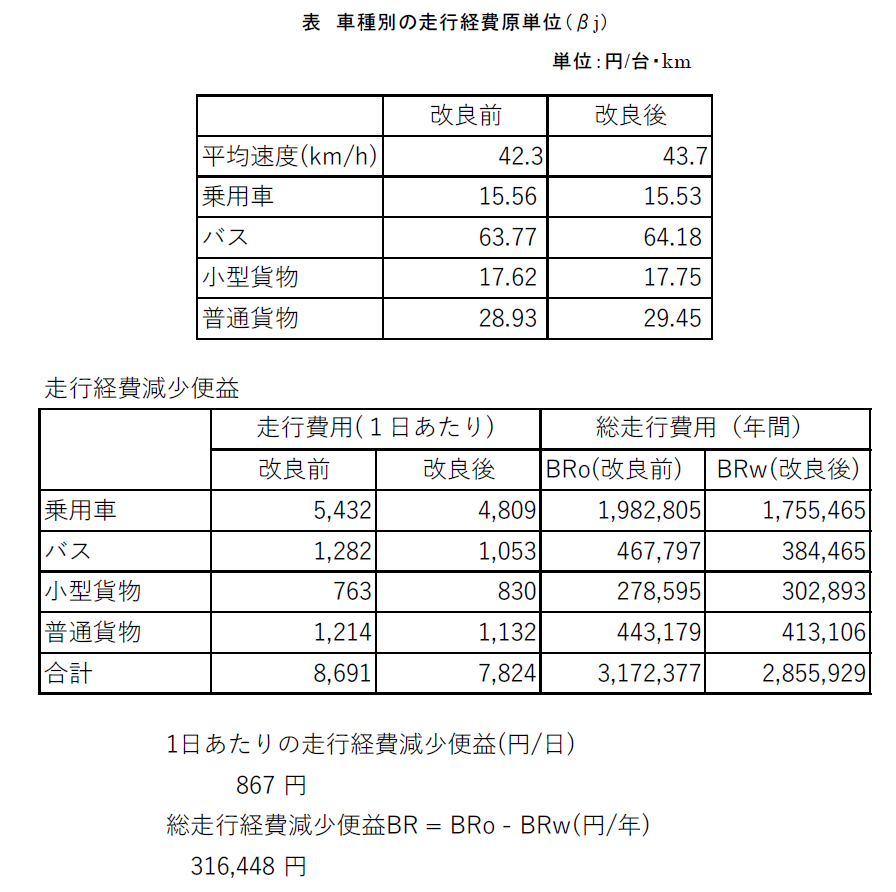 |
| ▲ある交差点に右折車線を設置することにより、平均速度や走行費用が改善することが分かった |
|